About Enhanced Index Document Matching (IDM) Fingerprints
Index Document Matching or IDM allows you to protect confidential information that is stored as unstructured data in documents and files. Data Fingerprinting is used to protect data such as Word, PDF, PowerPoint, or CAD documents.
Indexed Document Matching (IDM) is an effective method of detecting and protecting sensitive data. IDM indexes unstructured text within files, and detects when a user attempts to exfiltrate any part of the text or the entire file. The match is based on a percentage defined within the IDM Classification.
Unstructured or Index Document Matching (IDM) fingerprints work by content-matching indexed documents and images. With the Unified IDM, you can now fingerprint non-text-based files such as images. With these files, there is no text to extract instead, a digest match is performed for an exact match during policy evaluation.
The existing Structured (EDM) and Unstructured (IDM) fingerprints are still supported, but they are indicated as Legacy in the user interface.
You can also use tools provided with the DLP Integrator software to automate IDM (Enhanced) fingerprint updates.
How IDM Works
Potentially sensitive or confidential data is first identified by the organization and then fingerprinted by the Skyhigh Fingerprinting process. To train your data and generate an IDM (Enhanced) fingerprint file, you'll first need to install the DLP Integrator software (v.6.4.0 or later), which includes the IDMTrain tool. The tool extracts text from input files and normalizes the data. It then generates a series of overlapping hashes that represent the content. To produce these hashes, the file must have a minimum of 300 characters of text.
- If the content of the file is below this limit, a file can be matched with a whole file match. Whole file matching is available for all trained files.
- For files over this limit, the policy can be set to look for the document as a whole or just a percentage of its content.
For more details on preparing the IDM fingerprint, see Prepare the IDM Enhanced Fingerprint file.
IDM (Enhanced) Workflow
- Identify the documents or files you want to fingerprint and place them in the machine where the DLP Integrator is running to send to the IDM Train tool for processing.
- Create the IDM (Enhanced) fingerprint file and generate an index.
- Define classification criteria while you Create IDM (Enhanced) fingerprint (in the above step).
- Create a rule set with the IDM (Enhanced) classification criteria and apply it to a DLP policy.
- To change the match percentage for unstructured documents, configure IDM classification and repeat the above step (4).
Benefits of Unstructured Fingerprint
The following benefits of Unstructured fingerprints are applicable only for Enhanced IDM.
- Supported data includes the file types listed in Supported File Formats.
- IDM can reduce false positives with ignored text.
- API support to automate fingerprint workloads for real-time production.
- Archive files such as ZIP files are not automatically excluded.
- Each input file is limited to 500 MB, but multiple input files can be indexed together.
- Files less than 64 bytes are ignored.
- Files containing less than 300 characters will only be matched with an exact file match
- Files containing more than this limit can be matched with an exact file match or a percentage of its content
- Support for 200 million signatures. The following are the findings for various file formats and the amount of signatures (sigs).
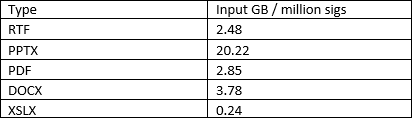
The first column shows how many GB of input data results in 1 million signatures.- For XLSX, you would be able to fingerprint 200 x 0.24 GB = 48 GB
- For PPTX, you would be able to fingerprint 200 x 20.22 GB = 4 TB
- For DOCX, you would be able to fingerprint 200 x 3.78 GB = 756 GB
- IDM Training Tool Support. The following are the details on Enhanced IDM support for files with Embedded objects (files):
- When objects(files) are embedded in a file, both the file and embedded file are trained as separate files. Embedded images, embedded files with no name, and embedded files with less than 64 bytes size are ignored.
- No limit on nested embedded objects, all embedded objects at different nested levels are trained as separate objects/files.
- Scanning Support. When files with embedded objects/files are scanned, the file and the embedded object are scanned separately and supported up to 100 nested levels.