Understanding the Central Management
Introduction
The goal of this document is to outline the best practices for having multiple Secure Web Gateway proxies in a Central Management cluster. After reading this, you will have a better understanding of how to manage your Secure Web Gateways, whether in a small cluster or on a large global scale.
What does it do
Central Management is used to synchronize the configuration (policy) between two or more Skyhigh Secure Web Gateway appliances. This is useful as it solves the problem of making duplicate changes on each appliance. Everything under the policy tab, along with the admin accounts,is synced automatically when creating the cluster. Each time a change is made and Save Changes is invoked the change will be propagated to all cluster members automatically. This allows the administrator to ensure that filtering policy is the same no matter which appliance is handling a given request. Settings under the Configuration tab are unique for each cluster node. This allows the administrator to assign separate networking configuration (IPs, routes, etc.) on each appliance.
Central management will also automatically sync a full configuration from every node to every other node in the cluster. This means that it is only necessary to take a backup on one appliance as that backup file will contain the full configuration for every cluster member.
What it doesn't do
While the term cluster is used to refer to a group of Secure Web Gateway's joined in Central Management, it should not be confused with the idea of a traditional proxy cluster. A Central Management cluster does not include any load balancing or failover functionality for end-user traffic.
Where’s my master
Secure Web Gateway operates using a master-less philosophy. As the whole purpose of the Central Management Cluster is to keep the Policy in sync throughout the cluster, you may log in to the Web UI on any node to make changes to the policy and the policy will be synced to every node instantly when saving changes. However, you may attach the GUI to only one node at a time in order to limit the possibility of conflicts. Therefore, it is recommended that a single node be chosen to be the Management node and all Administrators will only connect to that node to make changes. If a GUI is currently attached to one node and you attempt to login to a different node, you will be presented with the following screen along with a redirect URL directing you to the appliance that the GUI is currently attached to so that you may login:

Another tomcat is already attached to this cluster. Please log on to that one.
Please try to reattach to: https://10.10.73.71:4712/Konfigurator/request
Configuration
Prerequisites
The following is needed prior to setting up a Central Management cluster:
- Appropriate routes must be configured in your network to allow cluster communications. In case there are Firewalls between your Secure Web Gateways, you also need to ensure that the CM port (default TCP 12346) is allowed.
- A Cluster CA must be generated (if not don't already) under Configuration > Appliances, then click Cluster CA... A Cluster CA is used to authenticate the nodes in the cluster, each cluster node must must have the Cluster CA and key imported to be added to the cluster.
- Time must be in sync. Cluster communication is very dependent on this as this is how it knows which node has the most up-to-date configuration. It is highly recommended to configure NTP (Configuration > Date & Time) to handle this automatically. If you do not have an internal NTP server, you may usentp.webwasher.com
- All appliances should be running the same version & build. It is never recommended to mix versions in a Central Management cluster.
Settings
Configuration takes place under Configuration > Central Management. Under Central Management Settings, you will want to configure the physical IP address of the NIC that will be used for communicating in the cluster. It is recommended to stick with the default port of 12346, however, you may change it as long as it is configured the same on all appliances
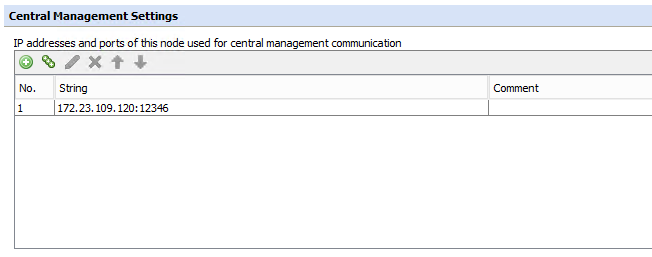
If you change your IP address under your network configuration, you must remember to update it here as well as it will not be updated automatically. Do not configure it as 0.0.0.0as that will not work either.
Node Priority
Node priority configures how the cluster will react when the policy is out sync. The node with a higher priority (lower value) would win in case of a conflict. If all nodes have the same priority, the node where the most recent change was made will win. It is recommended to keep all nodes with the same priority.
Group Definitions
Network
Network groups are used to control communication flow in a cluster. If all nodes are in the same network group, then all nodes will talk to all other nodes. The Network Groups can be thought of as a kind of routing of Central Management communication. Defining a unique network group for each physical location with one node in each location in a Transit group is recommended. All nodes in one location will then be forced to talk through the Transit node in order to communicate with the rest of the cluster.
Update
Update groups control how engine updates (URL Filter, AV DATs, etc.) can be shared throughout the cluster so that updates only need to be downloaded from the internet once. In general, it is best practice to have one Update group for each geographic location.
That way, nodes in the same location (fast connections, LAN links) can share URL Filter andAV Engine updates, while these updates are not shared between the different locations(slower connections, WAN links), and no bandwidth is utilized on these potentially largefiles.
Runtime
Runtime groups control how runtime data is shared. Runtime data includes coaching, quota, authorized override and pdstorage values. It is recommended to have a unique Runtime group for each physical location if users will be browsing through multiple proxies. If there is no overlap in the users accessing specific appliances, then it is recommended to put them into separate Runtime groups to reduce the overhead of information sharing.
Cluster CA
The Cluster CA is used by the Secure Web Gateway to authenticate nodes being added to the Cluster(this uses client certificate authentication). So, if you try to add a node to an existing cluster, the new node must have the Cluster CA loaded. Starting in 7.6.2.11+ and 7.7.1.4+, the Secure Web Gateway will now alert you if you're using a Default Cluster CA. Additionally, if you re-image an appliance, a Cluster CA will not be loaded; one must be generated first. To generate a new Cluster CA navigate to Configuration > Appliances, then click the button for Cluster CA. This will walk you through the steps of generating the Cluster CA, and will force you to save the CA and Key, keep these in a safe place.
If you try to add an appliance to the cluster without a Cluster CA, you will see the following error:
cannot add node because local node has no running listener available - new node would not be able to talk back to this node
If your Secure Web Gateway appliance is configured to use the default cluster CA, you will see the following error in your dashboard:
The Central Management Currently uses the default CA
[2018-11-13 13:57:14.671 -05:00] [Coordinator] [NodeRequestFailed] Message'<co_distribute_add_cluster_node>' on node 00000000-0000-0000-0000-0000000000FE (NodeAlias) failed with error '(301 - 'cannot connect') - "co_distribute_add_cluster_node: failure 'errno:111 - 'Connection refused'' while sending request - last action: connect"'.
Solution: The Central Management Currently uses the default CA (How to replace the default Secure Web Gateway cluster CA)
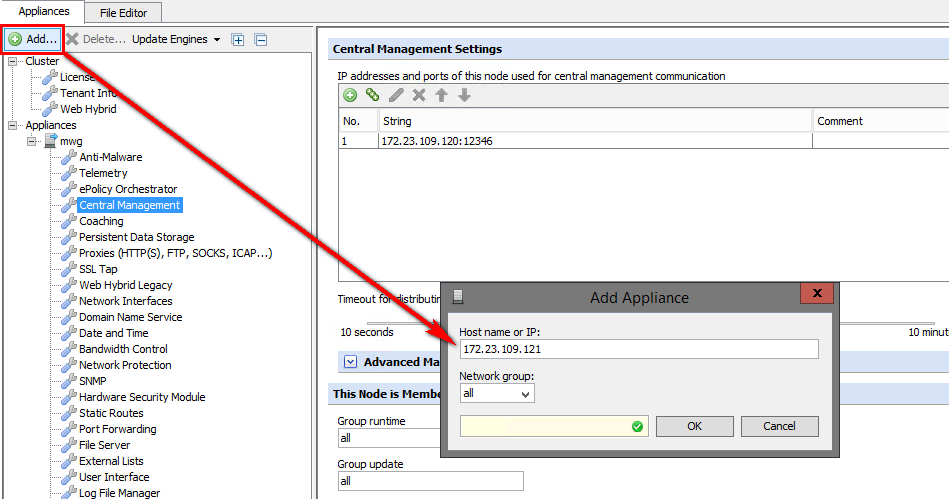
Adding a Node
Adding a node is as simple as going to Configuration > Add > enter IP of node to be added. Please keep in mind that the node that you are adding will have its policy overwritten by the node for which the GUI is currently attached (the one that you are logged in to).
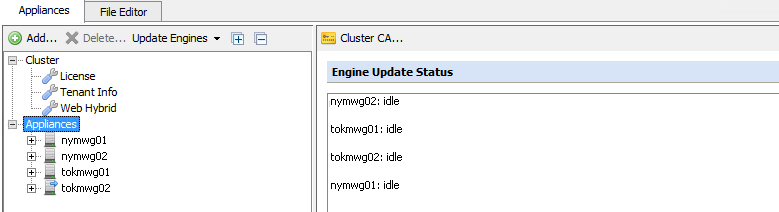
Once the nodes have been added to the cluster you will see them on the left side.
Please check the following on the Secure Web Gateway you are trying to add to the cluster:
- It has the same Cluster CA as the other appliances. That setting is located under Configuration> Appliances> Appliances> Cluster CA.
- You can telnet between that Secure Web Gateway and at least the Secure Web Gateway you are currently logged into.
You can test this on the CLI with the following command (test both directions):
From the CLI try the following as root:
ping and telnet ip-of-appliance 12346 telnet x.x.x.x 12346 x.x.x.x = Web Gateway IP Main Cluster device - Check port connectivity to appliances being added with command: #> nc -v -w5 < MWG NODE IP> 12346
Updates
The Automatic Engine Updates section configures how engine updates, including URL Filter, AntiVirus, CRL, Application Database, and DLP, are handled.
Enable automatic updates - This checkbox enables the local interval check for updates (like a cron job). When the interval time is reached, the local node will check whether the option for Allow to download updates from internet is enabled. If … from internet is NOT enabled, NOTHING will be done. No update is triggered. If it is enabled, the node will send a CM message to all other nodes (in its update group) and ask for their current list versions and whether they would like to receive updates.
All nodes that have the third option Allow to download updates from other nodes checked, will respond with their current version information. The updating node will then assemble a list of versions for the other nodes, including itself, and contact the update server with this information. The update server then sends the updates back with information about the nodes to update. The updating node then distributes the updates to the corresponding nodes in the cluster (or not if their versions are current).
Update packages are not stored within the cluster. They are for immediate delivery only. If a node with no current lists comes online and cannot do its own internet check, it will have to wait for another node to reach its update interval.
Example with two locations
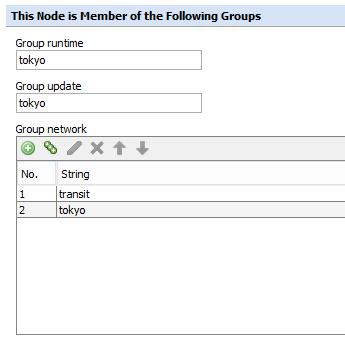
Here is an example cluster with 2 nodes in Tokyo and 2 nodes in New York City. Each location has its own unique Runtime and update groups with one node from each location in the Transit group.

Tokyo
tokmwg01
- Runtime: tokyo
- Update: tokyo
- Network: tokyo, transit
tokmwg02
- Runtime: tokyo
- Update: tokyo
- Network: tokyo
New York City
nycmwg01
- Runtime: newyork
- Update: newyork
- Network: newyork, transit
nycmwg02
- Runtime: newyork
- Update: newyork
- Network: newyork
Runtime groups should only be used for systems on the same subnet in same datacenter.
Example with a larger cluster
As a best practice, we recommend only putting up to 10 nodes behind a single transit node. If you have more than 10 nodes in a location, you should have more than one transit node and create smaller network groups that are tied to the transit node. Here’s an example with a larger cluster with nodes in Tokyo, New York, and Paderborn. For the smaller locations with one transit node, the runtime and network groups use the same name.

- Tokyo and New York are both runtime and update groups
- toknet1, toknet2, nynet1, & nynet2 are individual network groups
- paderborn is a network, runtime, and update group
Skyhigh recommends having at least 2 nodes from each network group in the transit group to sustain failure and serve as a fallback for cluster communications. The recommended 10-node guideline only serves as a baseline to effectively manage potential surges from resource-intensive features like PDStorage, Quota, Coaching, and Customer subscribed lists. It is possible to override the stated recommendation by limiting the usage of the aforementioned cluster-heavy features.
You should track the health of the Cluster and Cluster Management Communication Flow by monitoring the /opt/mwg/log/mwg-errors/mwg-coordinator.errors.log file and check for IPCAsyncQueueFull or overloaded issues.
Samples:
[Coordinator] [IPCAsyncQueueFull] Too many outstanding asynchronous requests, will handle message synchronous.
[Coordinator] [MessageWillRespondWithError] Will respond to message <co_distribute_set_custom_subscribed_content> with error: (901 - 'busy') - "Skyhigh Secure Web Gateway Coordinator is overloaded".
Common Questions
How do I verify my cluster is in sync?
This can be checked under Configuration > select Appliances (Cluster) on the left side. Then, look at the Appliances Information section on the lower part of the main pane. This shows the UUID (Universally Unique Identifier – unique per appliance), Name, Version & Current Storage Timestamp for all nodes in the cluster. An in sync cluster will show the same Current Storage Timestamp for all nodes.
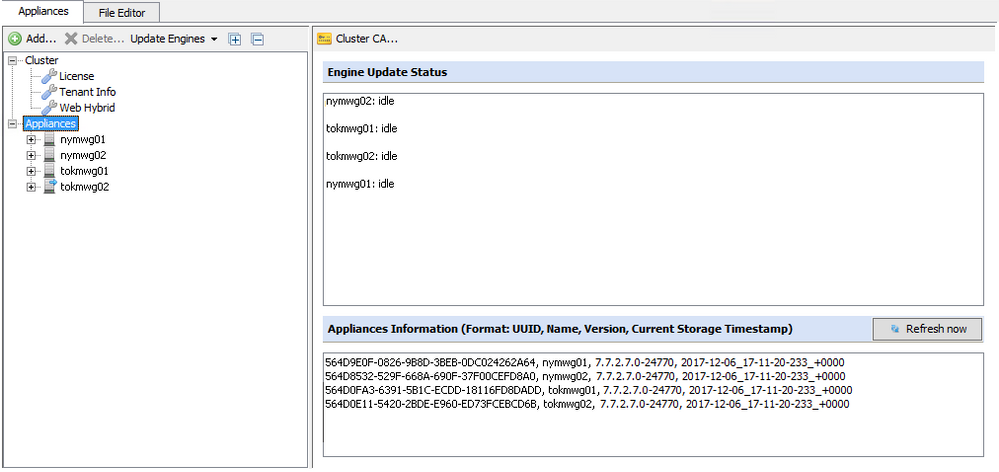
How do I troubleshoot connectivity problems?
Check for errors in the mwg-coordinator.errors.log found under Troubleshooting > LogFiles > mwg-errors.
Samples:
Time out of sync: [Coordinator] [NodeRequestFailed] . . . failed with error ‘(405 – ‘timedifference too high’)
Network problems: [Coordinator] [NodeRequestFailed] … failed with error '(301 - 'cannotconnect') - "co_distribute_init_subscription: failure 'errno: 113 - 'No route to host'' while sendingrequest - last action: connect
Why can't I add a node?
Most errors when adding a node should be self-explanatory. For example:
- No Local Listener Defined or No Cluster CA present: Add appliance failed: cannot add node because the local node has no running listener available - new node would not be able to talk back to this node
- Incorrect IP Specified or No Listener on Node That is Being e Added:co_distribute_add_cluster_node: failure 'errno: 111 - 'Connection refused' while sending request - last action: connect
- No or Wrong Network Group Defined on Node That is Being Added:[StorageConfigurationRejectedLocal] Configuration rejected by binary 'COORDINATOR' with status 'checking new settings failed - Invalid node path matrix /unreachable nodes'.
- Add appliance failed: co_distribute_add_cluster_node: ssl failure on message socket 14 while sending request - last action: certificate verification. -- The Cluster CA was changed on your primary node while your secondary node is still making use of the default cluster CA. It's found under Configuration > Appliances tab > select Appliances (Cluster) > then Cluster CA will show up to the right. Verify that if you select this Cluster CA button 'Secure Web Gateway Cluster CA' appears as the CA in use. If they are different, the CA in use on your primary node will need to be imported on your secondary node.
How do I check NTP or why is my time still off?
You can check your NTP settings from the GUI under Configuration > Date & Time. If your time is too far out of sync (more than ~1000 seconds) then NTP will not sync automatically. You can manually set the time for the GUI or use the following commands from the command line:
Force a sync (MWG 7.2 and earlier):
ntpd -s
Force a sync (MWG 7.3 and above):
service ntpd stop service ntpdate start service ntpd start
Note: ntpdate is also called to sync time at startup.
Log to the console so that you can verify that communication is taking place:
ntpd -d
Here is a good link to reference how NTP works: http://www.ntp.org/ntpfaq/NTP-s-algo.htm
How are conflicts handled?
- If it happens that two cluster nodes have different policy settings, first, the node priority is checked (higher priority/lower value wins).
- If they have the same priority, the one with the last/newest change wins.
How do I upgrade my cluster?
We recommend breaking the cluster to make each node stand-alone and upgrading nodes individually.
How do I create a region-specific policy?
You can add criteria to your rule sets that would be location specific. For example:
- Proxy.IP
- System.HostName
- System.UUID
If the locations use different IP schemes/subnets, you could also use Client.IP.
These criteria would be placed on top-level rule sets with all sub-rule sets contained inside. If you only have minor system differences in the regional policies (for example just different directories for authentication), it is easy enough to keep one global policy and make the changes in just the important rules. Here is an example with Top level region-specific policies:


What is a shared data error and should I be concerned?
You might notice the following error in your dashboard alerts intermittently. This"nuisance" error might stand out or could cause unnecessary alarm. This error will occur when a node in the Central Management cluster is not able to send it's shared data to another node in the cluster. This "shared data" can be classified as runtime data or dashboard alert data. Run-time data is described here;

Should I be concerned?
No. Given the frequency that this data needs to be shared in the cluster, it would not be unusual for this error to occur from time to time. This error is not something to be concerned with - especially if afterwards the dashboard shows a subsequent update indicating a successful synchronization:

Review your Runtime group configuration
As a best practice, Runtime groups should be implemented to ensure that runtime data is only shared amongst appropriate cluster nodes. Without runtime groups, the cluster nodes are unnecessarily synchronizing runtime data across all members of the cluster---which can increase the frequency of the 'Shared Data not synchronized' error. As described here, runtime groups should consist of nodes that service unique groups of users. For example, if North American users only reach Secure Web Gateways located in North America and European users only reach Secure Web Gateways located in EMEA, then the NA Secure Web Gateways and EMEA Secure Web Gateways should each belong to their own unique runtime groups. The unique runtime groups will prevent NA Secure Web Gateways and EMEA Secure Web Gateways from unnecessarily attempting to synchronize runtime data to each other.
Common causes
This error can also be prevalent under the following circumstances:
- Your Secure Web Gateways experience an intermittent network issue while one node attempts to transmit shared data to another node (i.e., TCP handshake failed or node wasn't reachable).
- While this can occur in any sized cluster, you're more likely to see this in a large cluster as there is a lot of information to share amongst nodes!
Policy Synchronization is not impacted
One important thing to know is that your "Policy synchronization" is not affected by this error. Your policy is passed between nodes in the "Storage Configuration" where you can see the following;

Additional debugging
If this error keeps happening after Runtime groups are validated as outlined above, then the error is likely due to failed attempts to synchronize dashboard alert data. If you want to check the specific cause of the error you can go and view the following log which will provide more information into the source of the issue:

You will want to look at the following log:

Here is an example error:
[2014-12-13 21:06:33.311 +00:00] [Coordinator] [NodeRequestFailed] Message '<co_distribute_shared_data_raw>' on node 564DAD79-A7BB-BCC2-55C0-58383C9557C7 (mwg75-2) failed with error '(301 - 'cannot connect') - "co_distribute_shared_data_raw: failure 'errno: 107 - 'Transport endpoint is not connected'' while sending request - lastaction: connect"'.
In this log entry, the "301 - Cannot Connect" denotes that node mwg75-1, couldn'testablish a tcp handshake with mwg75-2.
Samples:
Time out of sync: [Coordinator] [NodeRequestFailed] Message'<co_distribute_init_subscription>' on node failed with error ' (405 - 'time difference too high') -"time difference too high: 2019-03-12T09:57:48.687-07:00 / 2019-03-12T17:59:54.951+01:00"'.
Version mismatch: [2019-03-12 09:47:44.569 -07:00] [Coordinator] [NodeRequestFailed]Message '<co_distribute_init_subscription>' on node ( ) failed with error '(404 - 'versionmismatch') - "version mismatch"'
Network problems: [Coordinator] [NodeRequestFailed] … failed with error '(301 - 'cannotconnect') - "co_distribute_init_subscription: failure 'errno: 113 - 'No route to host'' while sendingrequest - last action: connect"'
Things to check for in cluster settings: distributionTimeout, distributionTimeoutMultiplier,allowedTimeDifference, checkVersionMatch and/or checkVersionMatchLevel don't have thesame value on all cluster members.
Configure Central Management in a NAT'D environment
For a NAT'D environment across firewalls or on the router or switch isolated networks, it must be done using names rather than IPs.
Locally the central management node names must resolve to the physical IP of the interfaces you are using, and on all the other remote/NAT's members of the management cluster the name must resolve to the NAT’d address. This is because when a node is joined to a CM cluster, the "local" node connects to the "remote" node and tells it to connect back to what evername or IP is configured locally. If the remote node cannot reach the local node by resolving the provided name or address, the clustering will not complete, and a java error dialog will be shown. All members of the cluster must be able to connect to all other members of the cluster using the chosen port, interface, and system names. This can be tested with telnet using the designated names. All the addresses can be loaded in etc/hosts to make this work. You do not have to change any DNS records, and the names do not need to match with DNS (and probably shouldn't). It is highly recommended that you have ACLs or firewall rules limiting the systems that can communicate on the chosen port to just the MWGs. Note that this will even work if the systems have the same private address subnet and different or matched domains as in the example below.
Example:
- Proxy1A management physical IP is 192.168.1.11; NAT IP is 123.123.123.11; domain isexample1.local; entry in central management is Proxy1A-mgmt.example1.local:12346
- Proxy2B management physical IP is 192.168.1.11; NAT IP is 123.123.123.21; domain isexample2.local; entry in central management is Proxy2B-mgmt.example2.local:12346
- Proxy3C management physical IP is 192.168.1.11; NAT IP is 123.123.123.31; domain isexample3.local; entry in central management is Proxy3C-mgmt.example3.local:12346
Configuration > File editor > hosts on Proxy1A.example1.local
192.168.1.11 Proxy1A-mgmt.example1.local
123.123.123.21 Proxy2B-mgmt.example2.local
123.123.123.31 Proxy3C-mgmt.example3.local
Configuration > File editor > hosts on Proxy2B.example2.local
123.123.123.11 Proxy1A-mgmt.example1.local
192.168.1.11 Proxy2B-mgmt.example2.local
123.123.123.31 Proxy3C-mgmt.example3.local
Configuration > File editor > hosts on Proxy3C.example3.local
123.123.123.11 Proxy1A-mgt.example1.local
123.123.123.21 Proxy2B-mgmt.example2.local
192.168.1.11 Proxy3C-mgmt.example3.local
- Configure MWG-A, MWG-B, and MWG-C so that their CM listening addresses are FQDNs
- Add a hosts-file entry to MWG-A, MWG-B, and MWG-C which resolves their own FQDNs to the physical IP address of their local NIC
- Add a hosts-file entry to MWG-A, MWG-B, and MWG-C which resolves the OTHER MWG'sFQDN to the NAT'd IP address
If you are using a separate management interface and subnet, you likely will need to add static routes for the NAT addresses as well. Also, remember to use groups as per above properly
Considerations
- Once a cluster is established, you can only access one GUI at a time
- All changes made by that GUI are synced to all other cluster members
- The system time is important in the CM cluster
- When a node is added to the cluster, the local time gets synced with the new node
- Going forward, if the times get out of sync (more than 2 minutes), CM communication will fail, and errors will be reported
- CM communication is time zone independent. UTC is used for CM
- URL, AV and CRL updates are fully controlled by the coordinator and therefore part of the CM
If you have more than one appliance and use Central Management, Skyhigh Security recommends that you remove all appliances from the Central Management cluster before you upgrade. You must remove each appliance separately and then update each appliance individually. After you have successfully updated all your appliances, add them back to the Central Management cluster.
Conclusion
In conclusion, you should now have the necessary information to manage your Secure Web Gateway Central Management cluster, no matter how big or small. You should also have a good foundation for starting to troubleshoot in the event of a problem.