Understanding ProxyHA (mfend - MWG < 8.2)
Overview
The idea of Proxy HA on Web Gateway is to introduce failover and load balancing without the need for external load balancers. This setup is only recommended for smaller deployments or locations/offices within a larger deployment where an external load balancer is not feasible.
Three components make up the Proxy HA functionality:
- A shared IP address (VIP) that the end user clients communicate with. The node that holds this VIP at any given time is considered the “active director”
- A kernel module on the swg that intercepts and routes traffic to scanning nodes (MFEND). Traffic that is not intercepted by MFEND will be handled by the OS as it would be without Proxy HA (for example SSH, UI traffic and so on)
- Scanning nodes that perform the “normal” SWG filtering
Set up
You should first join your appliances together in Central Management and then configure Proxy HA. Note that Central Management and Proxy HA are completely independent of one another, so the priority settings for Central Management have nothing to do with the priority settings for Proxy HA. In fact, you can create a cluster of appliances in Proxy HA without having them in Central Management, but then you run the risk of the rules differing between each appliance because they are not synchronized. We always recommend to have the appliances of a Proxy HA cluster also joined in Central Management.
Settings
To set up Proxy HA:
In the Web Gateway UI go to Configuration > Proxies (HTTP(S), FTP, ICAP and IM) under ‘Network Setup’ select Proxy HA.
Port Redirects
- Select “http” as the default protocol
- The “Original destination ports” must contain the proxy port the end users are pointed to.
- The “Destination proxy port” must contain the proxy port the swg service is using as its proxy port.
- Port redirects need to be ports that are actually listening. There cannot be a port listed in the port redirects area that is disabled in either the HTTP or FTP proxy port definition list. See the 'swg-mon' section below for further details.
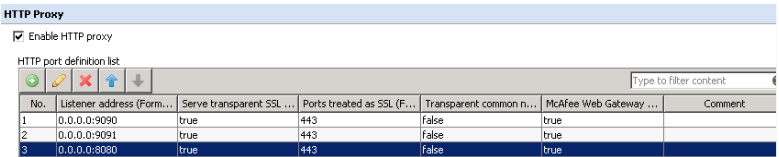
In other words, if your users’ browsers are pointed directly to Proxy port 9090 and the swg proxy port is also 9090, then we are going to redirect 9090 (original destination port) to 9090 (Destination proxy port) --see screenshot below:

Your proxy listener port must be unbound 0.0.0.0, binding the port will cause things to ProxyHA to stop functioning.
Director Priority
For example, 99 on the 1st swg appliance and 89 on the 2nd. In Proxy HA one of the nodes will always be the director = the one with the highest priority. It is not possible to have two directors in an active/active way.
Management IP
Local IP address of the node (do NOT configure a virtual IP address here). This IP address is used to auto discover the scanning nodes. All nodes have to be on the same subnet to be auto discovered.
Virtual IPs
This is the shared IP for the Proxy HA cluster which needs to be the same on all nodes in Proxy HA. Point your users’ browsers to the VIP.
Virtual router ID
Default is 51 and this also needs to be the same on all nodes.
This router ID is used by the VRRP health checks. If you have other devices on your network already using VRRP with router ID 51, make sure to change the router ID on your Web Gateways to something that is not used anywhere else on the network.
VRRP interface
eth0 is default. Only if you are using multiple interfaces or you are NOT using eth0 should you change this value.
How it works – More Details
Virtual IP (VIP)
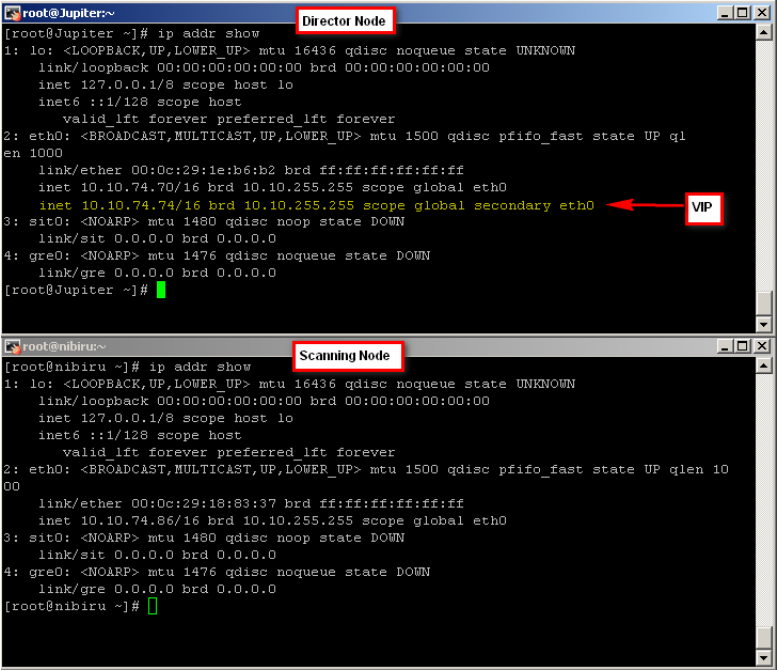
The VIP is an alias IP on the interface of the active director. The active director (the one that owns the VIP) takes ALL traffic from the clients and distributes this traffic to the scanning nodes (all SWGs involved on the same subnet). An active director node is also an active scanning node.
To verify which node “owns” the VIP, establish an SSH session with each node in Proxy HA and run the ‘ip addr show’ command. This will show you the active director and the nodes on standby:
Failover
VRRP is the protocol used for the health check amongst the pool of participating HA nodes and this is limited to a single subnet. The active director will send one multicast packet to 224.0.0.18 every second. If there is no multicast packet seen within 3 – 4 seconds from the active director, then failover occurs and the node with the second highest priority will become the active director. It informs the other nodes of its “director” or “master” state.
If this node goes down then the node with the next highest priority becomes director. Once the original Director comes back online (higher priority than the currently active director), it will resume its “master” state and take over the VIP once again.
Gratuitous ARPs are used to update the ARP tables of participating clients and routers. So every time the VIP changes ownership (failover occurs) the new director node sends a gratuitous ARP, the ARP tables are updated, and subsequent TCP/IP packets will reach the new director.
- VRRP errors and info about master/backup status can be found in:
/var/log/messages
Also during normal operation, you will see the active director send "protocol 253" packets to broadcast destination 255.255.255.255. Each scanning node will send "protocol 253" unicast packets to the IP of the active director.
Load Balancing
The Director node is receiving traffic from the clients and redirects it to scanning nodes on the kernel level using a built-in load sharing algorithm which takes into account resource usage and active number of connections. So if one scanning node is overloaded, the other will get more traffic to compensate. Generally load balancing is source-IP sticky, meaning the same client should reach the same scanning node. Normally, the active director is also an active scanning node.
swg-mon
- A health-check process that monitors the Proxy HA redirect ports you defined to ensure that they are available to accept incoming traffic.
- If a redirect port is not listening, then swg-mon detects this as a failure and load balancing will cease.
- Monitors all of the port redirects as a whole and not individually. See example below.
Example: Customer configures a successful Proxy HA set-up, which includes:
Proxy Listeners defined: 9090, 2121
Port Redirects: 9090, 2121
Later on, they disable the FTP proxy port 2121 listener while it's still listed as a Proxy HA port redirect.
Proxy Listeners defined: 9090
Port Redirects: 9090, 2121
swg-mon detects that 2121 is no longer listening and writes an error-message to /var/log/messages
Sep 28 05:53:01 PROXY1 swg-mon: current state: failure
At this point, the Proxy HA set-up is broken as SWG will no longer forward any traffic to this SWG. This includes the port 9090 traffic that is still up and listening.
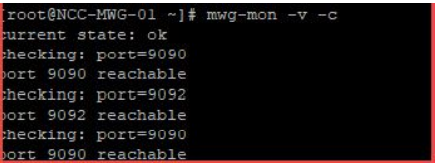
In the event that you're unable to determine what port is responsible for the error message, run this command:
swg-mon -v -c
Example output : Working Proxy HA set-up.All defined ports are must be reachable
Common Scenarios
Reasons why one box is getting all the traffic:
- No “Port redirects” configured on the director node. If there is no port redirect the network driver on the director node will not redirect the traffic, but handle it locally.
- All traffic is coming from the same source IP because there is a downstream proxy or a NATing device in place. Proxy HA load balancing is source IP sticky.
- The director does not know about other scanning nodes, you will need to review the HA configuration – use mfend, perhaps they are on different subnets ?
Which machine blocked the request?
To tell which machine handled/blocked a request, put the System.HostName property on the block page.
I would like to test something with one specific SWG in my cluster. Can I do that?
Yes! When HA is set up on the Web Gateways and one has to test a particular Web Gateway, you have to create a new Proxy port - for example 9091 on THAT Web Gateway. Then, in your Browser settings point the browser to :9091
Why is this necessary?
Because in Proxy HA we are forwarding (for example) ports 9090. Even if you point a browser directly to 9090, it will still be forwarded / handled via HA, meaning the director node will receive it and will either process that request itself or pass it to the scanning node, based on the mfend statistics. By creating an additional proxy port that is NOT forwarded, we can be sure that the individual Web Gateway to which the browser is pointed will process the test request.
What if I have want two independent Proxy HA Groups?
This is possible but requires a change on the CLI to the /etc/sysconfig/mfend file. The default load balancing ID (MFEND_LBID) is 51, so a unique LBID must be given to separate the proxy HA groups. Append the following line to the configuration file after the AUTO GENERATE CONFIG: MFEND_LBID='XX' where XX is the unique load balancing ID. For context here is the source discussion:
Troubleshooting
- Search /var/log/messages for VRRP errors and master/backup status
- Director node = Jupiter 10.10.74.70
- Backup director = Nibiru 10.10.74.86
- VIP = 10.10.74.74
- From
/var/log/messages on Nibiru (Backup node): takes VIP when Director (Jupiter) goes down....
nibiru Keepalived_vrrp: VRRP_Instance({) Transition to MASTER STATE
nibiru Keepalived_vrrp: VRRP_Instance({) Entering MASTER STATE
nibiru Keepalived_vrrp: VRRP_Instance({) setting protocol VIPs.
nibiru Keepalived_vrrp: VRRP_Instance({) Sending gratuitous ARPs on eth0 for 10.10.74.74
nibiru mfend: set lbnetwork 1
nibiru mfend: state=master previous=backup
nibiru kernel: TX Adding IPV4 Address 10.10.74.74
nibiru Keepalived_vrrp: VRRP_Instance({) Sending gratuitous ARPs on eth0 for 10.10.74.74
nibiru kernel: TX Scanning partner has failed 10.10.74.70
2. From /var/log/messages on Jupiter (original Director): comes back online, takes back the VIP.....
Jupiter Keepalived_vrrp: VRRP_Instance({) forcing a new MASTER election
Jupiter Keepalived_vrrp: VRRP_Instance({) Transition to MASTER STATE
Jupiter Keepalived_vrrp: VRRP_Instance({) Entering MASTER STATE
Jupiter Keepalived_vrrp: VRRP_Instance({) setting protocol VIPs.
Jupiter Keepalived_vrrp: VRRP_Instance({) Sending gratuitous ARPs on eth0 for 10.10.74.74
Jupiter mfend: set lbnetwork 1
Jupiter mfend: state=master previous=backup
Jupiter Keepalived_vrrp: VRRP_Instance({) Sending gratuitous ARPs on eth0 for 10.10.74.74
Jupiter kernel: TX Adding IPV4 Address 10.10.74.74
3. From /var/log/messages on Nibiru: shows transition from the acting director to back up as a result of step two
nibiru Keepalived_vrrp: VRRP_Instance({) Received higher prio advert
nibiru Keepalived_vrrp: VRRP_Instance({) Entering BACKUP STATE
nibiru Keepalived_vrrp: VRRP_Instance({) removing protocol VIPs.
nibiru mfend: set lbnetwork 0 nibiru mfend: state=backup previous=master
nibiru kernel: TX Removing IPV4 Address 10.10.74.74
VIP check on command line using ‘ip addr show’ command (see screenshots above)
‘mfend-lb -s’ ……command can also be used to see the current HA status.
mfend-lb -s
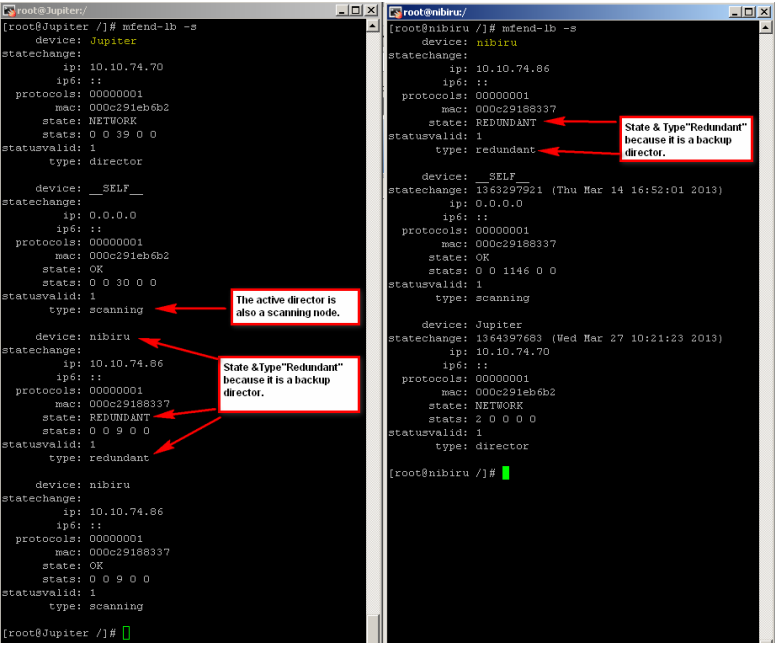
If you have 3 or more Web Gateways in ProxyHA together, the "mfend-lb -s" output on the active director will show itself and all scanning nodes. When run on a scanning node, the command output will show the active director and only the scanning node itself (not any of the other scanning nodes).