Health Check Incidents
Health Check Incidents
- A health check incident is raised when a server is found unhealthy with incident Id as 780.
- At any point in time, if the same server becomes healthy, another incident is raised with incident Id as 781.
- These incidents are visible in dashboard alerts.
- These incidents can also be sent to syslog and SNMP traps.
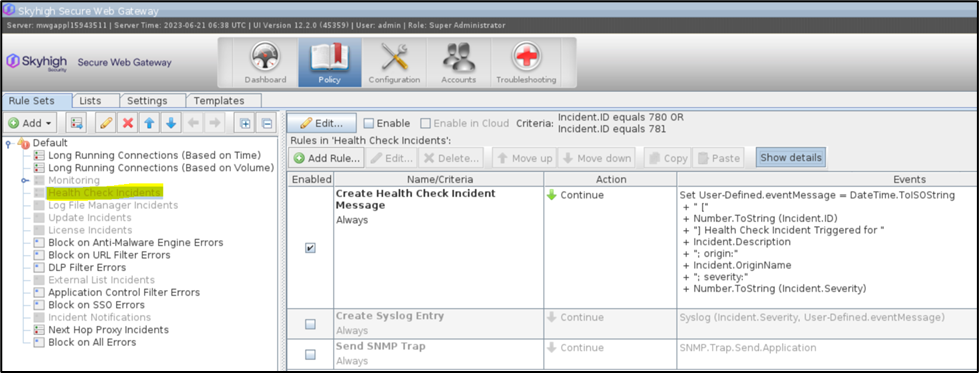
- A default ruleset is provided in the error handler for sending the incidents to syslog and SNMP traps. By default, this ruleset is disabled. The same ruleset is present in the ruleset library as well (Error Handling > Health Check Incidents)
Example syslog:
- 2023-05-15 05:38:09 [780] Health Check Incident Triggered: HealthCheck Failed for 10.140.250.105:9090 Connection timed out; origin: Proxy; severity:4
- 2023-05-15 05:38:19 [781] Health Check Incident Triggered: HealthCheck is now successful for 10.140.250.105:9090; origin: Proxy; severity:6
Dashboard Alerts-

Health Check Incidents Ruleset-
Health Check Incident alerting behavior in a cluster
There may be cases where the next hop proxies are not reachable from some of the SWG nodes in a cluster setup. In such cases, the policy containing the Next Hop Proxy rule would have an appropriate criterion. Health checks are independent of any policy.
Health checks will be running in the background for the configured next-hop addresses. The dashboard shows health check failure incidents when Health checks fail on the SWG nodes from where the next hops are not reachable.